
A History of Ai
Inference and Training


Andy Beach over on Engines of Change thinks about Ai in our modern context from a “who’s teaching who?” narrative. My post has taken a bit longer to produce, but hopefully you’ll find them complementary.
Artificial intelligence is ubiquitous in the media today as stock markets swell and user adoption of Ai applications like Claude, ChatGPT, CoPilot, and Grok eclipse the adoption even of mobile phones. It took me a bit longer to get this one ready to publish.Yet the idea of a mechanical thinking machine is an old one, dating back 300 years to Jonathan Swift who conjured the idea of a thinking machine in his famous book Gulliver’s Travels.1
It took more than 200 years to produce what we’d recognize as being a computer came into existence in 1939 when a pair at Iowa State College, Atanasoff & Berry, created the Atanasoff & Berry Computer (ABC). This computer utilized electronic circuits, ran on binary (0’s and 1’s), and separated the compute (logic) from data storage (memory). With this foundation they ignited the computer age. With more than 80 years of history there are many possible temporal and domain segmentations possible to enumerate the history of machine thinking. Ultimately, aside from the dates of specific accomplishments, most of this is a subjective narrative and one I invite participation and discussion about. My initial take on this is to break this continuum into eras large enough to make it digestible, but also to aggregate major developments.
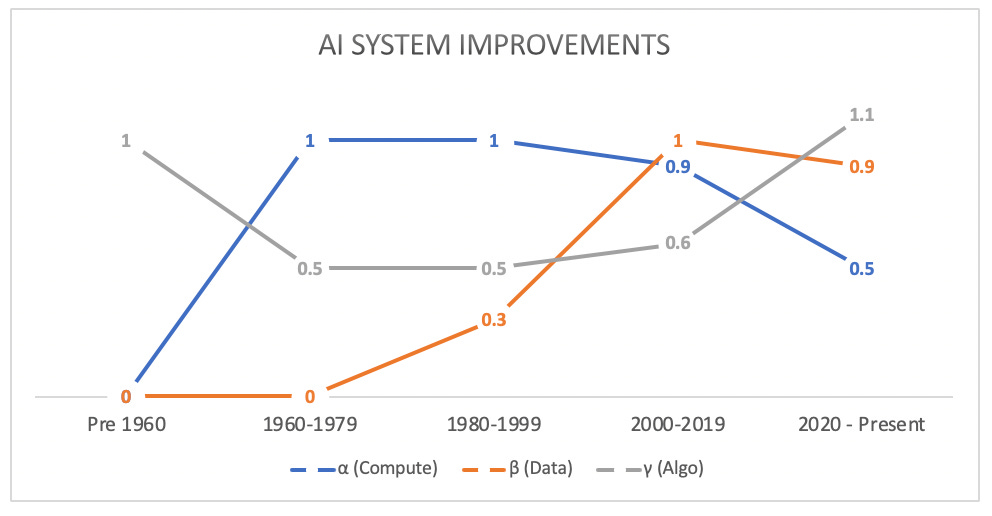
I created a subjective index using Amdahl’s law as my framework. For those unfamiliar, in brief Amdahl’s law describes an improvement in efficiency as being proportional to the percent of presence (use) in the overall effort. Basically, if something is used a lot and you speed that up, even modestly, you see big gains versus a massive improvement in something rarely used.
This is a subjective index and is not empirical. The intention is to provide a visual that represents the staggered improvements in fundamental Ai components (compute, algorithmic, and data) across the different eras. When compiling this I gained a new appreciation for just how constrained these systems had been waiting on data. Thus, its little surprise how the late 90’s and then the 2007 launch of the iPhone seemingly ignites a rocket ship of Ai progress.
Foundations of Computation and Early Neural Models (Pre 1960)
Incarnations of the modern computer date back to 1939 when a physics/mathematics pair at Iowa State College created the ABC computer. This system was electronic, rather than mechanical, utilized 0’s and 1’s (binary) rather than intergers (0-9) and separated logic (compute) from storage (memory) setting up the ability for each to scale independently. Then, in 1943, a psychology paper entitled “A Logical Calculus of the Ideas Immanent in Nervous Activity” was published creating the idea of an artificial neural network which would be first implemented in 1951 by Minsky & Edmonds in SNARC - their Stochastic Neural Analog Reinforcement Calculator. This device had 40 neuron-esque units which were used to investigate the effects of reward and punishment on animal behavior. Finally, in 1955 a research proposal for the Dartmouth Summer Research Project is written for a conference in 1956. This conference would birth a new term, as well as a research agenda, to advance the new field of artificial intelligence (Ai).
Milestones:
- 1939–1942: Atanasoff-Berry Computer (ABC): First electronic digital computer using binary logic and electronic switching for solving linear equations, enabling basic numerical inference for scientific computations.
- 1943: McCulloch-Pitts Neuron Model: Mathematical framework for artificial neural networks, modeling binary threshold logic for simple pattern recognition and inference.
- 1945: Stored-Program Architecture (von Neumann) shift from fixed-function to programmable systems.
- 1949: Hebbian Learning Rule: Algorithm for unsupervised training of synaptic weights in neural networks, foundational for associative learning and early weight adjustment during training.
- 1951: Ferranti Mark 1 Programs: Early AI software like Strachey’s checkers and Prinz’s chess programs ran on this stored-program computer, demonstrating search-based inference on general-purpose hardware.
- 1952–1962: Samuel’s Checkers Program: Self-improving machine learning on IBM hardware, using minimax search and alpha-beta pruning for training via self-play, achieving amateur-level inference. (ML parametric adjustment)
- 1956: Logic Theorist: First automated theorem-proving system on the JOHNNIAC computer, using heuristic search for symbolic inference and planning.
- 1958: Lisp Language: Developed for symbolic AI on IBM 704, optimizing list processing for recursive algorithms central to early training and inference in knowledge representation.
Symbolic Ai and Expert Systems Emergence - The Scoring Era (1960-1979)
As the cold war continued and corporations boomed computing technology grew modestly but as corporations grew and consumerism flourished so did the enterprise uses for technology. These workloads, typically single-record forward processing of statistical models, akin to giant spreadsheets of today, were batched in workloads of thousands to millions of rows and were mostly done ‘offline' for nightly or weekly reports. These workloads were run in familiar packages like SAS and SPSS, with custom development in COBOL, C, and Fortran. These model were targeted at credit-risk, insurance underwriting, early forms of fraud detection, and market research (segmentation) - think of PRICING strategies and managing financial RISK. A key highlight of this era was the world’s first ChatBot, ELIZA, developed at MIT which utilized pattern matching rules for NLP inference and was recently resurrected.
Milestones:
- 1961: Time-Sharing Operating Systems (CTSS) Allowed multiple users to interact with computers simultaneously (PDP-1)
- 1967: Stochastic Gradient Descent for Deep Nets: Amari’s method for training multilayer networks, addressing gradient computation for internal representations during backpropagation precursors.
- 1968: Group Method of Data Handling (GMDH): First deep learning algorithm by Ivakhnenko for training multilayer perceptrons via incremental layer addition, enabling approximation of complex functions.
- 1970: Reverse-Mode Automatic Differentiation: Linnainmaa’s algorithm (basis for backpropagation), efficient for computing gradients in neural training on limited hardware like PDP-10 minicomputers.
- 1974: MYCIN Expert System: Rule-based inference engine on PDP-10, using backward chaining and certainty factors for medical diagnosis, with ~500 rules trained via expert knowledge elicitation.
- 1977: BKG Backgammon Program: Feldman’s system on Cray-1 supercomputer, using Monte Carlo rollouts for training evaluation functions, defeating world champion via probabilistic inference.
Knowledge-Based Systems and Parallel Computing - Classification and Prediction (1980-1999)
These are the years when most of what we’d recognize today as computing would migrate from the realms of government labs, academic research, and enterprise basements into the consumer realm. Ai workloads of this time would be multi-class classification, time-series forecasts, and with the emergence of networks, electronic communications. Applications like MATLAB, R, and early Java ML libraries emerge which begin to empower the individual, rather than solely institutional workloads. With the boom in electronic communication SPAM filtering comes to be, OCR for document recognition, and risk models begin early forecasting of demand and financial predictions.
Unsurprisingly workloads remain CPU centric, but memory demands increase (feature vectors), processing is still primarily done in batches with SPAM filters beginning to achieve ‘near real-time’ performance. Building upon foundations of AI there is now a shift towards higher-dimensional data (text/audio) which necessitates a need for feature specific pipelines. Meanwhile, business value is concerned with conversion rates and operational efficiencies. The popular culture highlight of this era, which many of us will remember, was in 1997 when IBM’s Deep Blue beat world champion Gary Kasparov in chess showing the prowess of workload specific accelerated inference.
Milestones:
- 1981/85: Connection Machine: Hillis’ massively parallel supercomputer (65,536 processors), designed for SIMD operations accelerating neural network training and cellular automata inference.
- 1982: Fifth Generation Computer Project (Japan): Prolog-based parallel inference machines targeting logic programming, with hardware for concurrent theorem proving and knowledge base querying.
- Mid-1980s: Backpropagation Popularization: Widespread adoption on Lisp machines (e.g., Symbolics) for training multilayer perceptrons, overcoming single-layer limits via efficient gradient descent.
- 1989: Analog VLSI for Neural Nets: Mead’s neuromorphic chips (e.g., Intel’s ETANN), enabling low-power analog inference and on-chip training for real-time pattern recognition.
- 1994: TD-Gammon: Tesauro’s reinforcement learning on Sun workstations, using temporal-difference methods and neural nets trained via self-play for backgammon mastery.
- 1997: Deep Blue: IBM’s RS/6000 SP supercomputer with 480 chess-specific ASICs, parallel alpha-beta search (200 billion positions/sec) for game-tree inference, defeating Kasparov.
- 1997: LSTM Networks: Hochreiter-Schmidhuber’s recurrent architecture on standard CPUs, with gating for long-term dependency training, revolutionizing sequence inference.
Machine Learning Revival and Deep Networks - The Serving Era (2000-2019)
A new decade, century, and millennium deliver orders-of-magnitude improvements in computer performance as latencies move from milli-seconds (10^-3) to micro-seconds (10^-6). With ubiquitous corporate networks and long-haul WAN (Wide-area networks) after the dotcom collapse network computing begins to interlink programs across corporate networks giving rise to computational clusters and institutional and national boundaries with REST/RPC calls. As compute costs decline, network bandwidth becomes cheaper, and software becomes ubiquitous Machine Learning starts to grow as frameworks like Caffe and TensorFlow Server emerge and containerization technologies like Docker and Kubernetes bring software isolation to the mainstream.
Real-time recommendation engines become watercolor discussion topics as Netflix launches a competition for their personalization engine. Financial predictive models, specifically Ad click-through-rate (CTR) prediction, becomes increasingly popular as social networking booms. With the growth of social networking, smartphones and cameras image tagging in social media starts to present consumer side needs for content detection and moderation. With these capabilities, voice assistants also start to pepper the market.
The cloud era, workload acceleration, and horizontal scaling become de riguer. GPU Graphics processing units (GPUs) and tensor processing units (TPUs) accelerate convolutional neural networks (CNN) in image processing, horizontal scaling with the emergence of Amazon Web Services. Over-the-top streaming begins to boom pushing media processing workloads and media breaks out of its traditional broadcast confines. The distribution of technology brings about service level agreements, terms-of-service and build trust in federated systems where performance and reliability are essential. These changes also start to shift the financial structure of technology in the enterprise as costs move from capital expenses to operating expenses for leased compute. Observability becomes key as business value now becomes linked to performance as customer expectations and monetization opportunities increase.
The world takes notice in 2016 as DeepMind’s self-trained system AlphaGo defeats the Go world Champion demonstrating revolutionary inference on complex, intuitive games with policy and value network training.
Milestones:
- 2006: CUDA and GPUs for Training: NVIDIA’s framework on GeForce GPUs accelerated parallel matrix operations, enabling efficient stochastic gradient descent for deep net training (e.g., in AlexNet).
- 2012: AlexNet: Convolutional neural network trained on two NVIDIA GTX 580 GPUs, using dropout and ReLU for ImageNet classification, reducing errors via massive parallel convolution inference.
- 2015: Tensor Processing Units (TPUs): Google’s custom ASICs for inference acceleration, optimizing matrix multiplications for large-scale neural net deployment in production.
- 2016: ResNet and Highway Networks: Deep residual architectures trained on GPU clusters (e.g., 1000-layer nets), using skip connections to mitigate vanishing gradients during training.
- 2017: Transformer Architecture: Vaswani et al.’s model on TPUs/GPUs, with self-attention for parallelizable sequence training, foundational for training LLM and scaling language inference.
- 2017: AlphaGo Zero: DeepMind’s self-play reinforcement on TPU pods, training policy/value networks from scratch for Go mastery via Monte Carlo tree search inference.
Large-scale Ai and Generative Models - The Inference Era (2020 - Present)
The Ai curve pitches up, accelerating quickly as batch processing reaches petabyte-scale in feature generation for downstream models as real-time inference occurs on 100’s of millions to billions of mobile, IoT, and edge devices. Framework abstraction runtimes emerge (ONNX, TensorRT, OpenVINO) and model optimization, pruning, and distillation begins. Containers go serverless as Lambda and Cloud Run reduce inference pricing to highly-granular levels in the public cloud. LLM chat assistants and software programming code completion workloads emerge. Autonomous driving perception pipelines flourish, and health-care diagnostics at the edge become growth drivers.
Compute is now a booming field as workload accelerator research in (CPU + GPU, TPU, FPGA, NPU, ASIC) become increasingly common in AI deployments as latency expectations normalize as cloud infrastructure deployments grow. Meanwhile, energy efficiency begins to become a concern (especially on mobile device battery life) but also for data-center power/space/cooling as Ai systems start to consume entire power-plants worth of electricity. Co-design advantages of HW/SW frameworks (NVIDIA CUDA+GPU, ARM Ethos-U) and pay-per-use (driven by cloud monetization) on LLM inference, and edge licensing models become common. Competitive advantage now tied to performance and locality as Ai starts to be incorporated into more and more applications.
The 2022 launch of ChatGPT signals the meteoric adoption of consumer Ai as usage eclipses 100m users in a single month easily becoming the fasted technology adoption ever. Advanced AI Accelerators (NVIDIA) high-bandwidth memory, tensor cores optimized for AI inference and training diffuses into most Ai workflows catapulting NVIDIA’s stock.
Milestones:
- 2020: GPT-3 and T-NLG: Transformer-based models (175B/17B parameters) trained on GPU/TPU superclusters (e.g., Azure V100s), enabling few-shot inference for diverse tasks via autoregressive generation.
- 2022: ChatGPT: Fine-tuned GPT-3.5 on A100 GPUs, with RLHF for conversational inference, scaling to billions of parameters for real-time user interaction.
- 2023: GPT-4 and Gemini: Multimodal models on custom H100 GPU clusters, integrating vision-language training with diffusion processes for generative inference (e.g., text-to-image/video).
- 2024: Sora and Stable Diffusion 3: Video/text-to-image diffusion models trained on exaFLOP-scale clusters, using latent space optimization for high-fidelity generative inference.
- 2025: Edge AI 6G Ai native in the network.
https://www.ibm.com/think/topics/history-of-artificial-intelligence
Hey chief I saw @Andy Beach tag this in so was happy to find your stacks..
I’d gently like to contribute a bunch of stuff to this. I did AI at university when the subject was 50 years old (early 90s) and in reality not much has happened to AI in the time since.
Transformers (2017) were genuinely novel, but most of what’s happened since is scaling - more parameters, more data, more compute. That’s not the same as fundamental advances in how machines think or understand.
What you are really chronicling is the US history of the GPU.
to make it a history of AI, where’s:
• Turing and Colossus (UK, 1940s)
• Cybernetics and Norbert Wiener
• Ivakhnenko gets a brief mention but the Soviet/Eastern European contributions are glossed over
• British computing generally
The article conflates computational throughput with intelligence advances. Each era is framed as progress toward current LLMs, but it’s really just: “We got GPUs, then TPUs, then bigger clusters, now we have ChatGPT!”
This is why I think the modern phenomenon should be determined as EI (extended) rather than AI which would better be described as ‘autonomous intelligence’ and we are absolutely nowhere nearer that than we were 80years ago IMHO..
Brilliant. What if Swift's "thinking machine" had more direct infleunce on early engineers? We might've seen actual AI concepts emerge even faster than the ABC's foundational work.